Lean RAG: AI-powered Q&A Assistant for Private Docs
Do you have private documents and need quick answers to specific questions? Or are you looking for a way to extract insights from a collection of files in an organized manner?
Then Lean RAG might be exactly what you need.
Lean RAG is designed to serve as a Q&A assistant for private documents. By leveraging advanced AI technologies, the application processes uploaded documents, creates a searchable vector database, and allows users to interact with their data through a chat interface. It ensures fast, precise, and structured responses to user queries, offering an innovative way to engage with your content.
Links to the app:
Core Features
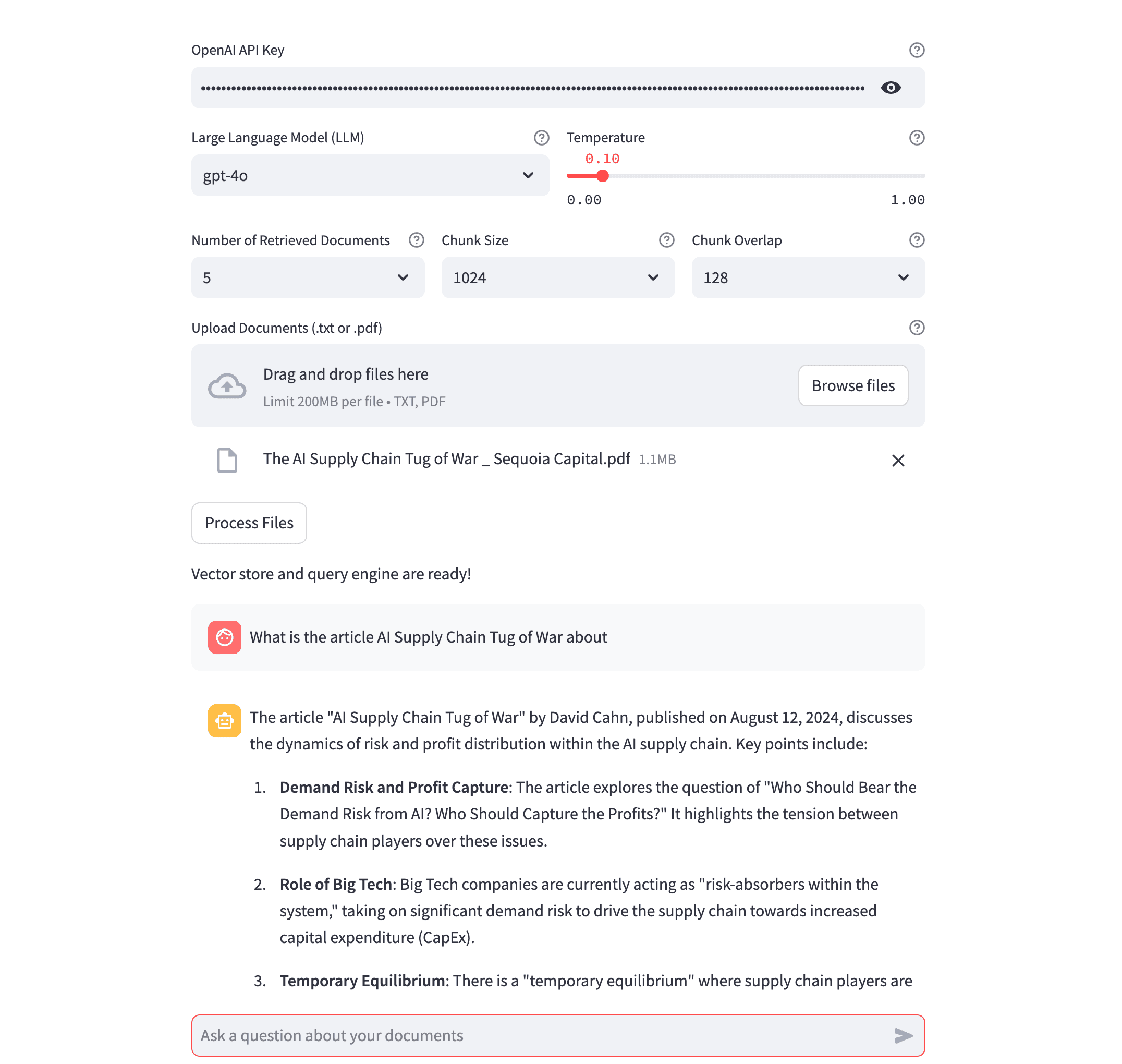
- Document Processing: Lean RAG accepts text (TXT) and PDF files, extracts content, and standardizes formatting for seamless analysis.
- Custom Vector Database: Uploaded files are processed to generate a unique vector database, enabling efficient and accurate information retrieval.
- Interactive Q&A Interface: Users can ask questions directly about their documents, and the system retrieves and displays the most relevant information.
- Configurable Parameters: Options to adjust token size, overlap, and the number of chunks retrieved during searches provide flexibility to meet various use cases.
- Session-Based Privacy: Data is stored in-memory during the session and deleted upon closing the application, ensuring user confidentiality.
Under the Hood - Implementation Details
1. Ingestion Service
- Approach:
- Accepts PDF and TXT files.
- Extracts and standardizes text content.
- Chunks text into segments (configurable size: 512-2048 tokens).
- Adds overlap between chunks for better context (configurable: 64-256 tokens).
- Tech Stack:
- PyPDF2 for PDF reading.
- LangChain for text chunking.
2. Indexing Service
- Approach:
- Generates embeddings for each text chunk.
- Stores vectors and original text in an in-memory FAISS index.
- Tech Stack:
- OpenAIEmbeddings for vector creation.
- FAISS for efficient vector storage.
3. Query Processing
- Approach:
- Converts user questions into vector embeddings.
- Searches for similarity matches in the vector database.
- Retrieves the most relevant chunks (configurable: top 3-10).
- Tech Stack:
- OpenAIEmbeddings for query vectorization.
- FAISS for similarity search.
4. Prompt Augmentation
- Approach:
- Combines retrieved context chunks.
- Constructs a structured prompt with context and user queries.
- Adds instructions for formatting the LLM’s response.
- Tech Stack:
- Custom prompt template.
- Logic for context assembly.
5. Retrieval-Augmented Generation
- Approach:
- Sends the augmented prompt to the LLM.
- Receives and formats the response.
- Displays results in the Streamlit chat interface.
- Tech Stack:
- OpenAI API (GPT-4o or GPT-4o-mini).
- Configurable temperature settings (0.0-1.0).
Conclusion
Lean RAG exemplifies the potential of integrating document processing with AI-powered Q&A systems. It transforms static files into dynamic, searchable resources, making information retrieval more accessible and efficient. Whether for personal use or business applications, Lean RAG is a powerful tool to unlock the value of your documents with the power of AI.