Transformer AI Models: The 5 Fundamentals of the Transformer Approach

#1 What are Transformers? A Quick Explanation of the Transformer Characteristics
When you hear the Tech and AI folks talk about the latest news around newest AI models, the terms “Transformer” or “Attention Mechanism” can frequently be overheard.
But what do they mean?
“Transformer” is the term for an AI model architecture that was introduced in 2017 by the famous Google research paper “Attention is all you need”. This architecture uses the “Attention Mechanism” to make better predictions. We’ll get to that a bit later.
Even more often than Transformer, you hear the term GPT, as it is also part of the term ChatGPT.
It is a more detailed description of a Transformer and stands for “Generative Pretrained Transformer.
The word “Generative” means that GPTs create new content and “Pretrained” that they are trained on large datasets and can be fine-tuned by additional training efforts. “Transformer”, as mentioned, refers to the unique composition, which is a specific Neural Network that makes use of the attention mechanism to improve the quality of results.
For reference, a Neural Network, like the GPT, is a category in the field of Deep Learning, which itself is one of the major areas of Artificial Intelligence (AI).
The Neural Network is structured like the human brain and also operates like one in some specific ways. They, for example, also have neurons, many little nodes of intelligence, like brain cells, which decide whether or not to capture information and send it across the network to eventually provide an impulse or some output.
#2 How have Transformers become so good? They use the Attention Mechanism
Transformers, like GPTs, are the main driving force behind the current AI hype cycle. But what is so groundbreaking about them?
As other AI models, Transformers are designed to generate new text or, alternatively images, audio, or video, based on patterns, which were previously learned from a very extensive training process with huge amounts of data involved.
Compared to earlier AI models, the Transformer uses the Attention Mechanism to improve the precision of its responses, for example, text generation.
But how?
It captures semantic relationships in the provided text, which can be a question. For that question, it analyzes how the single words relate to each other. This improves the understanding of the question and, consequently, the provided answer.
On the technical side and beyond the use of the attention mechanism, the Transformer makes use of parallelized computing.
This means essentially that the calculations, which are needed for determining the response to a question, are done all at once. This improves the speed at which these models can operate.
Like other AI models, Transformers are much like trained “engines” that take in inputs, push that through a learned logic and generate outputs in form of another text response.

The origin of the Transformer is in the field of language translation. This is the use case that Google’s 2017 research paper, which brought Transformers to the stage, was about.
However, many many different types of AI solutions can be built with transformers.
Just a few examples:
- Transcription of Audio to Text — done by Whisper AI
- Generation of new Images from Text — Midjourney, Stable Diffusion, Dall-E
- Generation of Video Material from Text — done by Runway ML
- Text generation from a Text prompt — of course, ChatGPT
#3 Let’s understand the “magical” approach: next word prediction — over and over again!
In most cases, Transformers are used to take text input and predict which text should come next.
And this is, plain and simple, done by a next word prediction.
Crazy right?
Repeating the prediction of the next word this leads to generation of whole sentences. This can be used to generate an answer to a question, a simple document completion or the translation of a sentence into a foreign language.
This prediction of suitable next words and, eventually, whole sentences happens based on a probability distribution.
As a result of its calculations, the Transformer model spits out probabilities that indicate which words are the likely candidates for being the next best word to an input text.
Quick simplified example:
We give the model the input “The grey cat is sitting on a green […]” and want the model to complete the sentence.
The model might generate options (i.e. the probability distribution) for the next best word like this:
- “tree” 70%;
- “car” 25%,
- “garage” 5%.
From this set of options, the word with the highest likelihood is chosen by the model to be the best output, which in the example is “tree” with a probability of 70%.
It might be very strange to think about probabilities, when we have the goal to generate a useful response from text input like a prompt or a question.
However, this iterative process of predicting the next best word and doing that repeatedly until a complete text is produced, is what essentially happens when interacting with a Transformer model like ChatGPT.
#4 How is a Transformer Trained to Reach Quality? Pre-Training, Fine-Tuning, Inference
To be able to use such a high-quality Transformer for text generation, it needs to be developed and trained first.
Significant training efforts with lots and lots of data are needed to come up with such a Transformer model, that can reach the quality of ChatGPT.
Generally, we can distinguish between two main stages for AI and also Transformer models: training and inference.
In the training stage, two major steps are used for the leading Transformer models like the one underneath ChatGPT — it’s the pre-training and fine-tuning.
Pre-training is a general training effort to develop a general level of intelligence. This is done based on huge amounts of data, for example, data from the whole internet.
The fine-tuning step is specialized training, for example, targeted to train the model towards a certain task. This can be Question and Answering like in ChatGPT, Language Translation like in DeepL or Text Summarization used by the tool TL:DV.
Regardless of the nuance of the use case, the underlying logic for the mentioned solutions is based on the fundamentals of the Transformer.
The second stage, inference, is the actual usage of the model, where it uses the learned logic to generate a response from an input or a prompt.
#5 The Billion Parameter Question: How Model Quality depends on the Parameter Count
The quality of the generated text highly depends on the training efforts.
But the other important factor is the structure of the Transformer model. Two important factors here: the structure and amount of model layers and the amount of model parameters.
The model layers, which are steps that the input passes through before resulting in an output, will become more important in Part 2 and Part 3 of this Mini Series.
For now, the focus is on the parameters, also called weights. They are the bespoke neurons, which submit information within the Neural Network structures. Through the training process these parameters or neurons can learn from the training data, like a human would do.
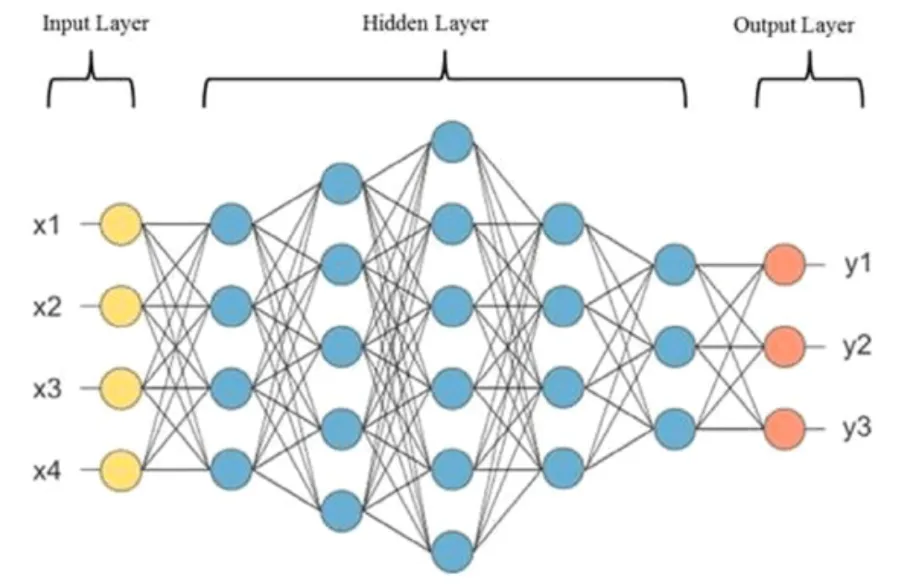
Of course, the more neurons a human brain has, the better, since more complex information and relationships can be captured, and more complex tasks can be handled.
Likewise for the Transformer model: the more parameters a model has, the more logic in can soak in and the better the prediction results will be.
An earlier version of the ChatGPT model, GPT-2, was not performing very well based on standards of human understanding.
It generated text that was not considered to be a good response to a question or a prompt. The reason, amongst others, was that it was only trained on 2 billion parameters and didn’t have the depth of cutting edge models nowadays.
A newer version, GPT-3, was already much better, since it had about 175 billion parameters that it was trained on.
GPT-3.5, which fueled the successful ChatGPT version of November 2022, which created the big Wow effect, had the same number of parameters like GPT-3 but was trained with more advanced techniques. As we remember, it was the first Transformer model that showed such advanced capabilities that it was perceived to be useful for all kinds of human knowledge work. It consequentially reached mass adoption quite quickly.
Summary: What we’ve learned so far
In this article, we have learned the fundamentals of Transformer AI models.
#1 Transformer Characteristics: GPTs are Generative Pretrained Transformer models in the realm of Neural Networks, which operate similar to the human brain.
#2 Attention Mechanism: They use the attention mechanism that captures the relationships between words in sentences to increase semantic understanding of the model and output quality.
#3 Iterative Next Best Word Prediction: They iteratively generate predictions of the next best word from a probability distribution of possible words.
#4 Pre-Training, Fine-Tuning, Inference: They gain their capabilities from a training stage with pre-training and fine-tuning to be able to generate output during the inference stage.
#5 Parameter Count and Structure of Layers: The model quality is achieved by complex training as well as complex model architecture including high parameter count and multiple layers of processing to capture as much logic from the training data as possible. Parameter count is a deciding factor for model quality, just like amount of brain cells in a human.
These are great fundamentals to further build on.
Let’s continue our learning from here onwards!