18 Transformer Building Blocks of the Attention is All You Need Paper Explained

Introduction
In my previous article, we’ve looked at the 5 most important characteristics of how a Transformer models works — those were important fundamentals to advance our knowledge.
Now, we take it a step further. Under the hood of the Transformer model, we find different building blocks that bring a Transformer model like ChatGPT to action.
We will go through them in the same sequence that a Transformer model also uses them to carry out its tasks, such as language translation.
For a quick glimpse at them, I’ll provide a TL:DR, but recommend to read the deep dive further below.
TL;DR
For a Transformer model, the steps shown in the architecture picture from the 'Attention is all you need' paper (further below) are needed to generate accurate text for instance, a translation from English language to German.
The model conducts several transformations from text to numbers and to many more numbers and uses several calculations to learn about relationships between words in the input sentence and the generated output.
I’ve summarized the steps that the Transformer is carrying out for a language translation form English sentence (e.g. “The grey cats sits on the green tree”) to the German equivalent in the following sequential overview:
Processing of the English Input Sentence (Encoder Part)
#1 Input: Transform input from words (“artificial”) to tokens (“artifi”, “cial”) and into numeric token IDs (7657, 15986).
#2 Embedding: Change token IDs (7657) into a multidimensional vector (=list) of many numbers that captures the semantic meaning of the token [0.9875857587, -0,1087608768, …, 2.0097860986, -0.978687857]).
#3 Positional Encoding: Add the values of a similar same-sized vector carrying information about the position of words in the sentence to the embedding (#2).
#4 Encoder Block: Transform the embedded input by applying multiple calculation blocks that include Attention, Feed Forward, and Add&Norm steps
#5 Multi-Head Attention: Analyze which tokens are important for each other in the input sentence (i.e. shared relationships and dependencies) and add the info to embedded token vectors — serves as a step to check how tokens communicate with each other
#6 Add & Norm: Create a pattern of adding results of each layer on top of each other to show cumulative results without recalculation of entire blocks to achieve traceability; normalize results to keep numbers in certain “healthy” range
#7 Feed Forward: Digest and process the information from Multi-Head Attention by sending them through a Neural Networks where tokens are processed individually — serves as a step to provide additional computation to the earlier learned relationships and dependencies
Translation into German Output Sentence (Decoder Part)
#8 Output (shift right): Tokenize the parts of the translation output that has already been generated and capture the respective token IDs
#9 Embedding: Embed token IDs of the output into multidimensional vector
#10 Positional Encoding: Add vector about of tokens’ positional information of the so far generated output
#11 Decoder Block: Transform input by applying multiple identically structured blocks that include Masked Decoder Attention, Encoder-Decoder Attention, Feed Forward, and Add&Norm layers
#12 Masked Multi-Head Attention: Analyze which tokens of the so far translation output are important for each other (i.e. shared relationships and dependencies) and add this info to embedded token vectors
#13 Add & Norm: Add results to the chain of previous results and normalize
#14 Multi-Head attention: Analyze which tokens in the input sentence (=encoder) are important for any token of the output translation (=decoder)
#15 Feed Forward: Digest and process the information with a Neural Network
#16 Linear: Change format of results from the decoder block to have one value entry for each possible token in the vocabulary (highest value = likely next token)
#17 Softmax: Transform values into percentages representing likelihoods
#18 Output Probabilities: Determine ID of next selected token and turn into word
The crazy thing is that this process is repeated word for word, and the model is able to generate a very accurate translation by applying this approach.
How is that possible? By factoring in the new context for every word prediction. For every new word that is being generated, the last words that has just been provided milliseconds ago is already considered to come up with an accurate prediction of the next word.
You will get more detail in the following deep dive.
Deep Dive: Transformer Blueprint with 18 Building Blocks
Let’s go back one step first. What is the basis for all of this?
The concept and technical blueprint of the Transformer model has been introduced and thoroughly described by Google’s research paper “Attention Is All You Need” from 2017. This can be described as the “Bible of Modern AI”.
Based on this paper, we are now going to learn in a bit more detail, but still in simple language, about the Transformer model’s building blocks and how they interact with each.
Thanks to the non-technical language, we’ll boost our understanding of this.
So let’s dive in.
Here is the blueprint picture of what we call a Transformer:
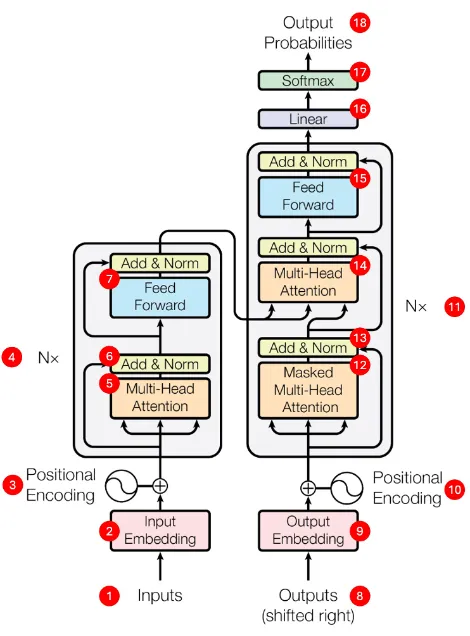
Practical Example
We'll use the translation example:
- English: "The gray cat sat on the green tree"
- German: "Die graue Katze saß auf dem grünen Baum"
This example uses an encoder-decoder architecture like in the original Google paper. ChatGPT uses a slightly different decoder-only architecture, covered in Part 3 of this series.
The Encoder Path (Blocks 1-7)
In the encoder path, we've discussed the steps from the encoder block to the feed forward neural network, which helps the model understand the input sentence.
We start with step #1, the Input, which is the English sentence.
#1 Inputs
The inputs are in most cases a sequence of so-called tokens, which can be words, subwords (=like syllables) or sometimes even single characters.
If you consider our example sentence “The gray cat sat on the green tree”, all those words are not split further into smaller parts, so a word equals a token. You can just think of words every time we use the term token. But in some models longer words like “alphabetical” might be broken up into 2 or more tokens like “alphabet” and “ical”.
This process is described as tokenization and the resulting tokens are indexed. What does this mean? Every token will be associated with a number (a token ID) like in a dictionary. The dictionaries in ChatGPT, for instance, carries about 50.000 possible tokens. In that case, it’s a mix of words and syllables.
The token IDs for the words of our example sentence “”The gray cat sat on the green tree” can look like this: 464, 12768, 3797, 3332, 319, 262, 4077, 5509.
In the following building blocks of the Transformer only the token IDs will be used to represent words. The model can only calculate with numbers, not with text.
For many models, the token IDs will not be stored in the format as above, but in form of ones and zeros in a “sparse matrix”. This is the result of the so-called “one-hot encoding” process where each token will have 50.000 values associated with it — 49.999 zeros and only 1 one, namely for the matching value, which is equal to the token. The word “tree” with its token ID 5509 will have a one at the position representing “tree” and 49.999 zeros at all the other positions (“cat”, “car”, “flower”, all the words and syllables of the vocabulary).
#2 Input Embedding
Each token is transformed from the token ID (or a one-hot encoded sparse matrix) into a multi-dimensional sequence of numbers, which is called embedding.
This embedding step produces a dense vector (=a collection/list of numbers). This can be 512 numbers per token, but also much more or much less. 512 is the number of dimensions and, essentially, provides 512 possible ways to describe a token (= a word).
But why go from one token ID to a long list of numbers (=multiple dimensions) for a single word?
The Transformer model will need to store lots of information about each token. This is, primarily, the semantic meaning of the token, such as whether it is a verb, an adjective, an animal, a sports activity, etc. Later, also the position of the token and it’s relationship with other tokens gets added. This all can, of course, not be represented in one number. More numbers per token are needed to have more room for learning and storing their information.
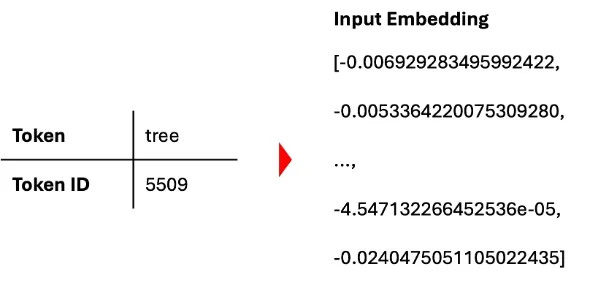
For the word “tree” in our sentence the related token might be ID 5509. The embedding vector could look like above. Please note that this is a shortened form with 4 out of 512 or more dimensions.
#3 Positional Encoding
When starting to process the input sentence, the Transformer doesn’t actually know the order of tokens in the input sequence and processes them all at once.
It needs to use a specific method to be able to tell where each token is in the sentence to also consider that information for the translation.
Is the word “tree” in first, second, third or in another position in the sentence? This is important to understand to capture the meaning of each word in the context of the sentence.
By adding a positional encoding mechanism based on mathematical functions, the model describes the position of a token in the input sentence. This is added to each token’s embedding numbers that were generated in the previous step.
The result is a vector similar to the one before, just with other numbers, since the values of positional encoding were added:

#4 Encoder Block (Nx)
The encoder block (Nx in the picture) is a wrapping of identical layers. The blocks repeats itself multiple times. In the original Transformer architecture from the “Attention is all you need” research paper, there are 6 encoder blocks stacked on top of each other.
Each block processes the information from the Input and Positional Encoding stage in two major ways:
Figure out which tokens in the sentence are most relevant to each word (Multi-head Attention), and… Pass the information through a small Neural Network (Feed Forward) to digest and process the acquired information to sort out semantic meaning and the relationships between tokens in the sentence These steps together with the supporting steps of Addition and Normalization (”Add & Norm) are wrapped together in each encoder block.
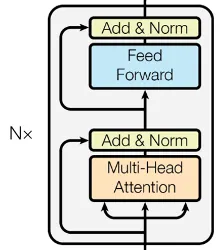
The Encoder block, essentially, brings together communication between tokens (attention mechanism) with raw computation (feed forward) into one layer, which is grouped and replicated multiple times for achieving better and better results.
#5 Multi-Head Attention
The attention step is probably the most important innovation in the Transformer approach.
It is the logic where the model looks at every token in the input sequence (for instance the word “green” in our translation example) and compares it to all the other tokens in the sentence (“The gray cat sat on the [..] tree”) to determine which other tokens are more or less in relationship with the token in question (“green”). We can say more practically that the model checks, how much “attention” should be given to the other words in the sentence when analyzing the context of one specific word.
In the example, the model might focus more on the tokens “tree” and “the” when looking at relationships for the token “green”.
“Multi-head” in multi-head attention means that the model does this check for token relationships multiple times in parallel, each time with a different focus. One check could be “which related adjectives in the sentence have an influence on the token I am looking at?”. Or another one: “which pronouns do have an influence on the token?”.
#6 Add & Norm
“Add & Norm” are important helper steps in the encoder block, but also later in the decoder.
“Add” stands for an approach that is applied to the model, which adds results of each step on top of each other instead of doing complicated calculations across multiple building blocks.
Essentially, the model adds more logic resulting from each calculation on top of each other. This has a key advantage: it enables reconciliation of what has happened in each of the steps of the process. This is crucial for training the model. The visible cumulative path (=also called the “residual connection”) of which results have been added in which step enable training mechanisms to optimize the model performance.
“Norm” stands for Normalization and means that the Transformer rebalances calculated values to prevent extreme numbers from influencing the calculation results. The values are rescaled to be distributed around 0 (i.e. with mean of 0 and standard deviation of 1). This helps the model to learn more consistently.
#7 Feed Forward
After the model has figured out which tokens are important for each other, it passes the updated and normalized values of each token through a stage of Neural Network layers.
We remember from Part 1 of the Mini Series that the Transformer has a large number of neurons, the so-called brain cells of the model. Using the Neural Network in the Feed Forward step gives the brain cells of the Transformer some time to digest the input and process the learned relationships.
In this step, the core activities are mathematical operations like matrix multiplications and applications of polynomial functions. This is done individually for each token and helps the model to advance its intelligence and understand the semantics, such as the sentence context and token relationships.
The Decoder Path (Blocks 8-18)
For the decoder path (right side in the picture):
#8 Outputs (Shifted Right)
The initial step of the encoder part is also done by the decoder under “Outputs (shifted right)” step. This time for the parts of the sentence that have so far been generated.
Let’s say the Transformer model has already translated part of the English sentence “The gray cat sat on the green tree” into the German words “Die graue Katze […]”.
The model then stores only the initial part “Die graue Katze” into a form of numerical values. This initial part is the only existing information it can work with to predict the next token.
The token that is currently predicted by the model is always the position right next to the outputs, which have already been generated. After the prediction of the token, which will eventually become “saß”, the focus will be shifted right, to the next token, and the output “saß” is now taken into consideration to increase the context to “Die graue Katze saß”.
#9 Output Embedding
Like in the encoder, the output tokens are turned into multi-dimensional vectors of numbers to store information about their meaning and relationships.
#10 Positional Encoding
Information about the order of the tokens that were already generated as part of the translation (for instance, “Die graue Katze saß”) are added.
#11 Decoder Block (Nx)
The decoder is also made up of several identical blocks (usually 6, just like in the encoder), but each decoder block does not 2, but 3 main things:
It looks at the part of the output sentence that has already been generated and captures meaning and relationships between each of the tokens, It pays attention to the meaning and relationships of tokens in the encoder part (=the untranslated input sentence) and carries that information over to the translation side to ensure that the intended meaning from the input is preserved It, again, refines the learned logic and relationships of the output using a small Neural Network for processing These three steps allow the decoder to understand both the input sequence (the English sentence) and the context of what it has already generated for the output (the German translation).
These steps together with supporting functions of Addition and Normalization (”Add & Norm) are wrapped in each decoder block.
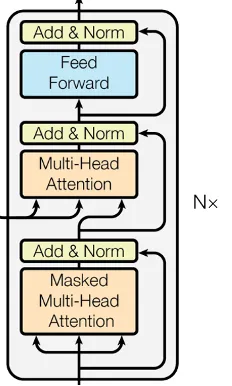
The decoder also unifies communication — this time within the decoder itself and across both sides, encoder and decoder — with computational efforts to stabilize the learned patterns.
#12 Masked Multi-Head Attention
When the decoder is generating an output on a token-by-token basis, which eventually becomes a sentence, it obviously can’t see into the future of what tokens it will predict.
Consequently, in its calculations, the Masked Multi-head Attention uses masking to make sure that the model can only make calculations based on the tokens that have already been generated.
Let’s think about it: in the encoder, the model has received the full English sentence as input — all at once. Therefore, the attention mechanism can analyze all tokens against each other to identify meaning and relationships for the whole input sentence.
In the decoder, it does not receive the full translation at once but must generate it token by token (=word by word).
So, it’s like the multi-head attention in the encoder, but with a restriction to only be allowed look at past words — those which were generated so far.
There is one minor difference between the model training and the inference (=usage).
Remember from Part 1 of the Mini Series, we have training (pre-training and fine-tuning of the model) and inference (the actual model usage).
For training, the model learns on past examples, where it sees, which English sentence has been translated to which German one. For those examples, it theoretically has access to the full sentence, even for the decoder.
During training it has to “mask” the future parts of a translated sentence in the examples, so that it can only see the sentence, which it has generated until that point. Afterwards, it can compare by referring to the real training example, whether that token that was generated was appropriate.
#13 Add & Norm
The decoder, for traceability, also processes the results of each step as an addition to the previous step’s result and normalizes the numbers to avoid extremely high or low values and potential strange calculation results.
#14 Multi-Head Attention
Next, the Multi-Head Attention layer allows the decoder to pay attention not only to the so far generated output sequence but to the full input sentence, meaning the English sentence on the encoder side.
It looks at every token in the output sequence and checks whether any token of the input sentence and has some relationship with it.
This process figures out, which words in the input sequence are most relevant to each token in the output. More abstractly, the English tokens influence the prediction of the German tokens based on how directly they are connected in meaning, grammar, or structure with the German translation so far.
This type of attention mechanism is called “cross-attention” because the calculations are considering inputs across both sides, the encoder and the decoder. All other attention mechanisms of the Transformer are “self-attention” mechanisms as they only focus on either the encoder or the decoder inputs, but never both at the same time.
#15 Feed Forward
Like in the encoder, this is another small Neural Network that helps to process the captured information for each token and, thereby, advance the model’s understanding.
#16 Linear
Once the decoder blocks have processed the information, the last one passes it’s result to a linear transformation layer.
This layer converts the token representations (=still multi-dimensional vectors for each token) into a form that the model can use to predict the next token.
It reduces the multi-dimensional vector output down to something that has the format of a vocabulary base.
For ChatGPT models, the linear layer transforms the decoder output into a vector (=a list) of approximately 50.000 different numbers — one for each possible token in the vocabulary.
Each number indicates a score and the tokens with highest scores are interesting candidates for the prediction of the next word. The value vectors for tokens are called logits.
#17 Softmax
This step turns the output of the Linear layer from a vector of 50.000 values per token into one of 50.000 probabilities, meaning values between 0 and 1. Those can be interpreted as percentages, where, for example, 0.2 means 20%.
In a simplified example the recommended next token prediction in the German translation after “Die graue Katze saß […]”, might be “auf” with a chance of 60% and “in” with a chance of 20% chance and so on.
#18 Output Probabilities
Finally, the probabilities coming out of the Softmax steps are used to choose the appropriate next token in the sequence.
The intuitive logic would be to just pick the one with the highest probability. But there are various approaches to do that.
An alternative to focus on the top candidates is one which tries to chain multiple token predictions together and then evaluate which sequence makes the most sense collectively based on a joint scoring.
Whatever the chosen logic is, the token ID for the selected next word is spit out and can be transformed into text based on that ID.
Summary and Key Takeaways
That’s it — the process of translating an English sentence to German using a Transformer AI model.
That certainly was a lot. Congrats on making it through all the steps.
What did we learn?
We’ve gained a detailed understanding of how a Transformer AI model works — a model, very similar to the one that powers ChatGPT, which kicked off the recent AI hype — very likely the biggest Technology transformation since the rise of the internet.
If you have questions, need more clarification, or would like to discuss a topic, please contact me through my profile.
Have a good day — bye!